
티스토리 뷰
● 도입
- 해시테이블은 프로그래밍 언어에 따라 이름이 조금씩 다르다.(Hash, Map, HashMap, Dictionary 등)
- 해시테이블은 단어 그대로 Hash와 Table이 합쳐진 자료구조이다.
- 표를 영어로 Table 이라고 한다. 그렇다면 여기서 Hash는 무슨 뜻인지 알아보자
● Hash(구글링해서 정리)
- 그 유명한 ChatGPT에게 hash에 대해 알려달라고 해봤다. 나름 정리를 잘 해줘서 번역해봤다.

- 해시 데이터 구조(hash data structure)는 항목별로 고유한 키를 사용하여 데이터를 테이블 형식으로 구성하고 저장하는 방식이다.
- 해시 함수를 사용하여 각 key-value 쌍에 대한 고유한 인덱스를 생성하므로 항목의 빠른 조회, 삽입 및 삭제가 가능합니다.
- HashTable의 효율성은 해시 함수의 품질뿐만 아니라 테이블의 크기와 저장된 항목의 수에 따라 달라진다.
- HashTable은 데이터베이스 색인, 기호 테이블, 캐시 구현과 같은 작업을 위한 컴퓨터 과학 및 프로그래밍에서 일반적으로 사용된다.


- 아래는 내가 구글링으로 찾은 결과이다.
- Hash란 데이터를 다루는 기법 중 하나, Hash Function은 데이터의 효율적 관리를 위해 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
- 즉, 임의의 크기(길이)를 가진 데이터(Key)를 고정된 크기(길이)의 데이터로 변환한다.
key : 매핑전 원래 데이터의 값
Hash Value(= Hash Code) : 매핑 후 데이터의 값
Hashing : 키(key)와 값(value)으로 매핑되는 과정 자체
- 데이터 검색 시 사용할 Key와 그에 해당하는 Value가 한 쌍으로 존재하며 이러한 Key 값이 배열의 인덱스로 변환되기 때문에 검색과 저장의 평균적인 시간 복잡도가 O(1) 이다.

- HashTable은 key-value가 하나의 쌍을 이루는 데이터 구조이다.
- HashTable은 key를 hash function으로 계산한 결과값을 배열의 인덱스로 사용한다. 이때 hash function에 의해 반환된 값을 해시값 또는 해시코드 라고 한다.
- 즉, key 값을 hash function을 이용해 배열의 인덱스로 바꿔주고 그 자리에 데이터를 저장한다.
- 위의 사진을 글로 정리하면 아래와 같다.
원래 데이터의 값(Key)
↓
Hash Function
↓
Hash Function의 결과 = Hash Code
↓
Hash Code를 배열의 Index 로 사용
↓
해당하는 Index에 data 넣기
cf) 아래 글에서 참고했다.
https://hee96-story.tistory.com/48
[자료구조] Hash/HashTable/HashMap
해시(Hash)/해시 함수(Hash Function)/해싱(Hashing)? 해시(Hash) 란 데이터를 다루는 기법 중 하나이며,해시 함수(Hash Function) 는 데이터를 효율적으로 관리하기 위해서 임의의 길이의 데이터를 고정된 길
hee96-story.tistory.com
https://en.wikipedia.org/wiki/Hash_table
Hash table - Wikipedia
From Wikipedia, the free encyclopedia Associative array for storing key-value pairs Hash tableTypeUnordered associative arrayInvented1953Algorithm Average Worst caseSpace Θ(n)[1] O(n)Search Θ(1) O(n)Insert Θ(1) O(n)Delete Θ(1) O(n) A small phone book a
en.wikipedia.org
● HashTable

- 프로그래밍에서 위의 표를 어떠한 방법을 통해 저장하고 표현할 수 있을까?
- 가장 쉬운 방법은 배열을 이용하는 것인데 등번호를 배열의 index 라고 가정하면 아래와 같은 모습이 된다.

- 그러나 위와 같은 table은 문제가 있다.
- 등번호를 index로 사용하다보니 index[2], index[7] 등과 같이 중간에 빈 공간이 생긴다.(낭비되는 공간)
- 또한 만약 등번호가 90번인 선수가 있다면 그 만큼의 크기를 갖는 배열이 있어야한다.(당연히 빈 공간은 더 늘어난다.)
- 이러한 문제를 어떻게 해결할 수 있을까?
- 등번호를 어떠한 계산을 거쳐 한 자릿수로 만든 후 index로 저정할 수 있다면 공간 낭비가 줄어들 것이다.
- 이때 어떠한 계산을 하는 함수를 해시 함수라고 한다.
- 위 표의 상태일 때 등번호를 10으로 나눈 나머지를 index로 사용하는 해시 함수가 있다고 했을 때 해당 해시 함수를 거친 후의 표는 아래와 같다.

- 이런식으로 해시 함수를 통해 table의 index를 새로 만들기 때문에 HashTable 이라는 이름이 붙었다.
- ※ 주의 : index를 새로 만든다는 것을 간과하면 안 된다. inedx를 사용한다는 것은 여전히 배열의 개념을 바탕에 깔고 있다는 것
- 위의 HashTable에서 등번호를 10으로 나눈 나머지 값이 key, 이름은 value에 해당한다.
- 등번호만 알면 선수의 이름을 알 수 있듯이 HashTable은 key만 알면 value를 알 수 있기에 O(1)의 성능을 가진다.
(데이터의 CRUD 모두 O(1)의 성능을 가진다.)
- 그러나 이런 HashTable에도 문제점이 존재한다.
- 위의 예제에서 등번호를 10으로 나눈 나머지를 반환하는 해시 함수를 사용해 배열의 index를 구한다고 했다.
- 현재 index[1] 의 자리에는 이미 데이터가 있는데 등번호가 21번인 선수가 있다고 해보자
- 해시 함수를 이용하면 21 또한 나머지가 1이 된다.
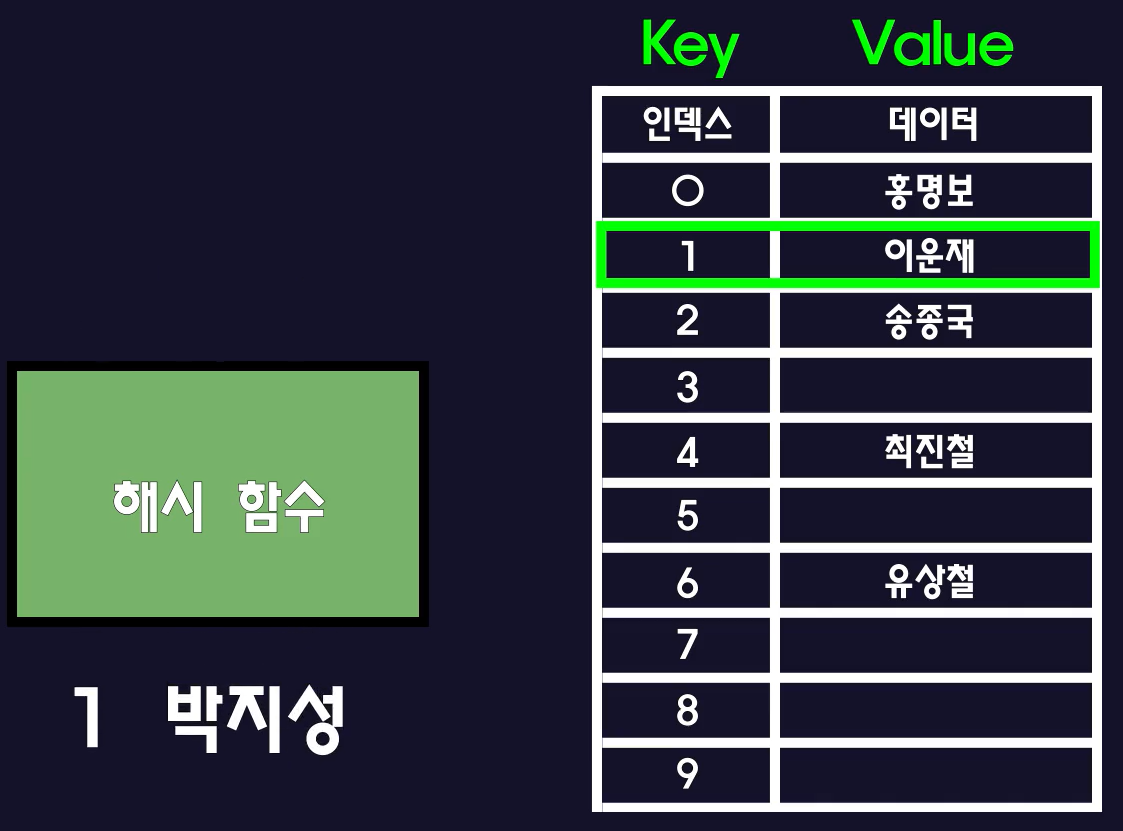
- 이러한 경우를 충돌(Collision)이 발생했다고 한다.
- 충돌은 어떻게 해결해야 할까? 충돌이 발생할 때마다 기존의 데이터를 버리자니 그건 너무 일차원적이다.
- 강의에서는 충돌을 해결하기 위해 value를 연결리스트로 구성해 데이터들을 연결하는 방법을 얘기했다.
- 아래와 같은 구조라면 기존의 데이터와 새로 들어온 데이터를 모두 동일한 index에 저장할 수 있다.
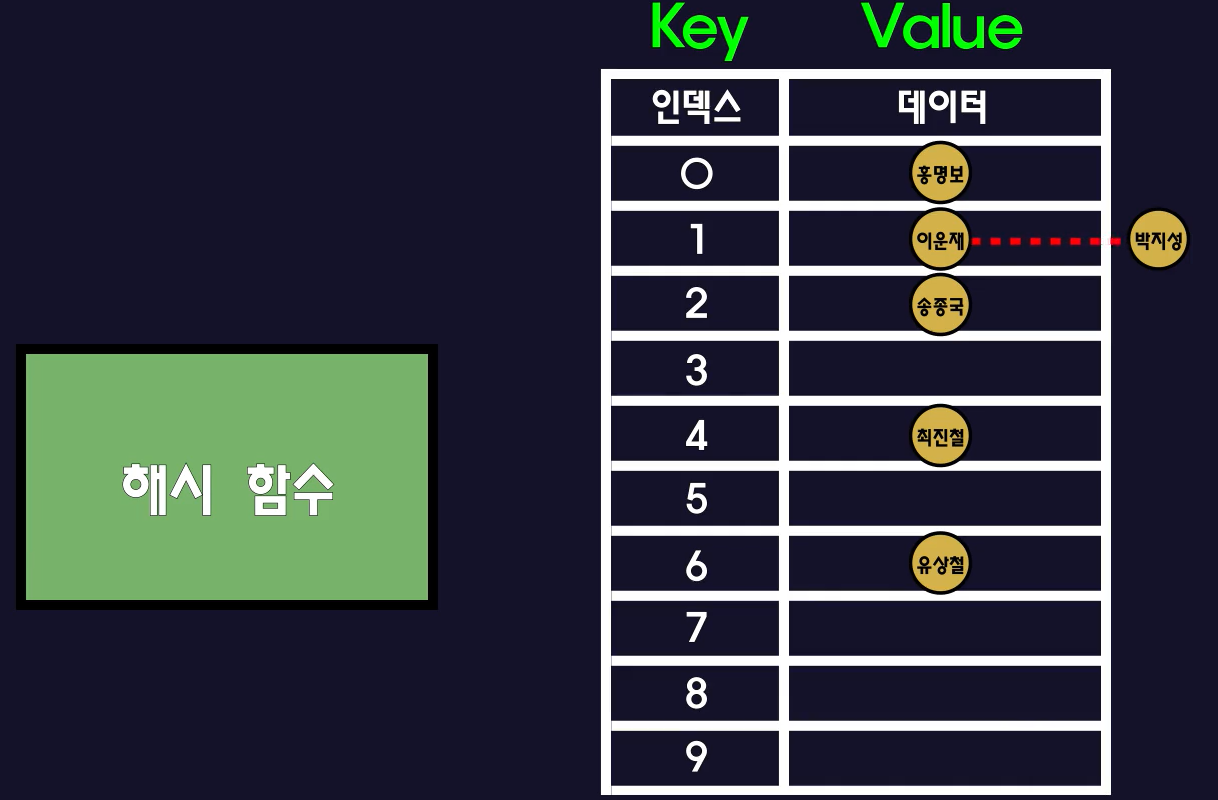
- 만약 내가 '박지성(= 영원한 캡틴, 해버지)'이라는 데이터를 읽고 싶다면 아래와 같은 과정을 거치게 된다.
1. (key = 21번)으로 읽기 요청이 들어왔다.(박지성의 등번호가 21번이라고 가정)
2. 해시 함수를 거쳐 배열의 index[1]에 접근한다.
3. index[1]에는 연결리스트로 21(박지성)과 1(이운재) 2개가 저장되어 있으므로 해당 key(21번)의 데이터를 만날 때까지 차례대로 접근한다. 참고로 이때는 O(n)의 성능이다.
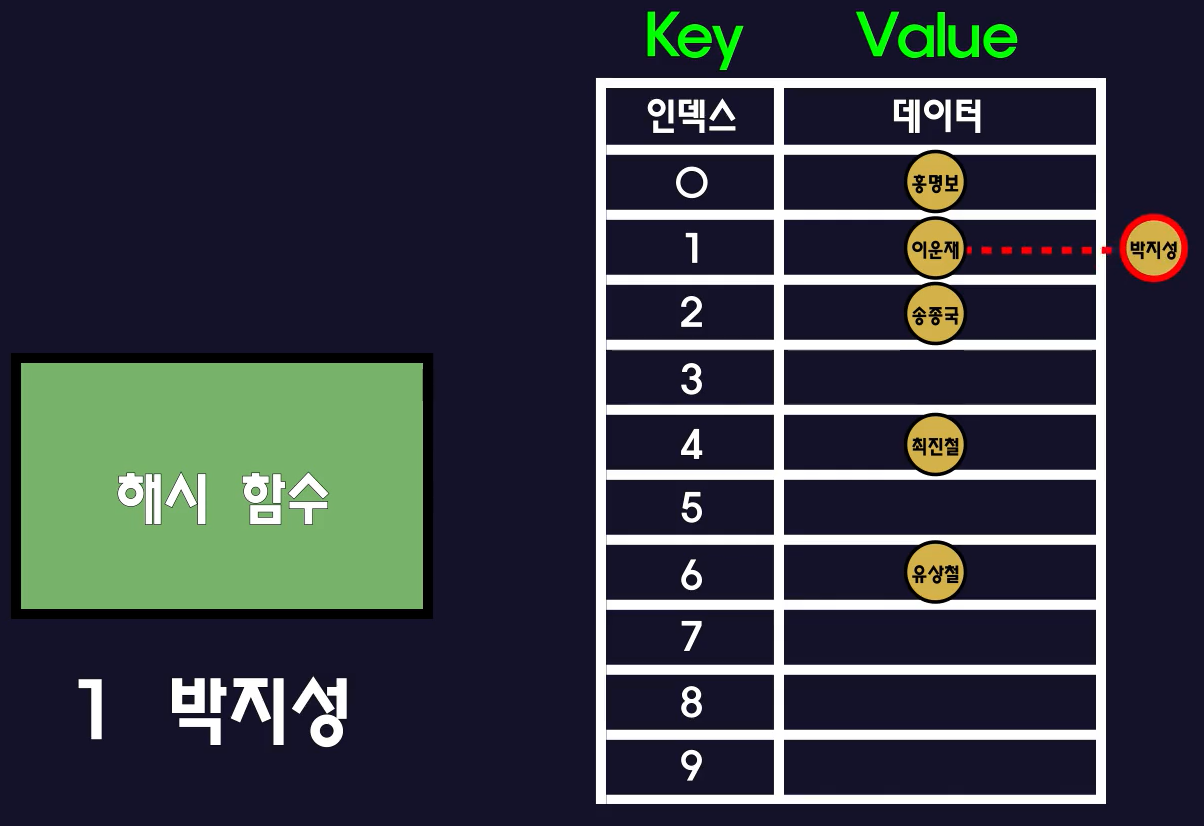
- 여기서 유념할 점은 HashTable 자체는 CRUD에서 O(1)의 성능을 가지고 있어도 만약 index에 해당하는 데이터가 여러개라면 결론적으로 O(n)의 성능을 가질수도 있다는 것이다.
- 즉, 충돌이 많아질수록 탐색 시간 복잡도가 O(1)에서 O(n)으로 가까워지는 것이다. 그렇기에 HashTable에서 해시 함수의 선정은 매우 중요하다.
- 좋은 해시 함수는 하나의 index에 데이터 겹침 없이 데이터를 골고루 분배시켜주는 함수이다.
| 장점 | 단점 |
| - 빠른 데이터 탐색, 삽입, 삭제 | - 메모리를 많이 차지한다.(공간을 많이 차지) - 해시 함수에 따라 공간의 낭비가 극대화 될 가능성 - 해시 함수가 핵심이기에 좋은 해시 함수 구현이 필수 |
'CS > 자료구조 및 알고리즘' 카테고리의 다른 글
| #10 선택정렬(Selection sort) (0) | 2023.03.04 |
|---|---|
| #9 버블정렬(Bubble Sort) (0) | 2023.02.23 |
| #7 큐(Queue) - 개념(FIFO : First In First Out) (0) | 2023.02.05 |
| #6 Stack(스택) - 개념(FILO : First In Last Out) (1) | 2023.02.02 |
| #5 연결리스트(Linked List) - 개념 with 노드(node) (0) | 2023.01.25 |
- Total
- Today
- Yesterday
- nosql
- db
- MongoDB
- API
- Phaser3
- DART
- java
- SpringBoot
- 프로그래머스
- node.js
- 알고리즘
- SQL
- Stream
- git
- jpa
- OS
- 프로세스
- Java8
- spring
- 빅데이터
- 자료구조
- 코테
- Phaser
- Advanced Stream
- 코딩테스트
- 빅데이터 분석기사
- MySQL
- Spring Boot
- 메모리
- 운영체제
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |