
티스토리 뷰
● 연결리스트(Linked List)
- 이전 글에서 작성한 배열의 단점을 어떻게 극복할 수 있을까?
- 똑똑한 사람들이 아래와 같이 생각했다.
- 배열이 연속된 메모리 공간을 할당하는 것이 문제이니까 저장하려는 데이터들을 메모리 공간에 '분산'해서 할당하면 되지 않을까? 그리고 이렇게 분산된 데이터들을 서로 '연결'해주면 되지 않을까?

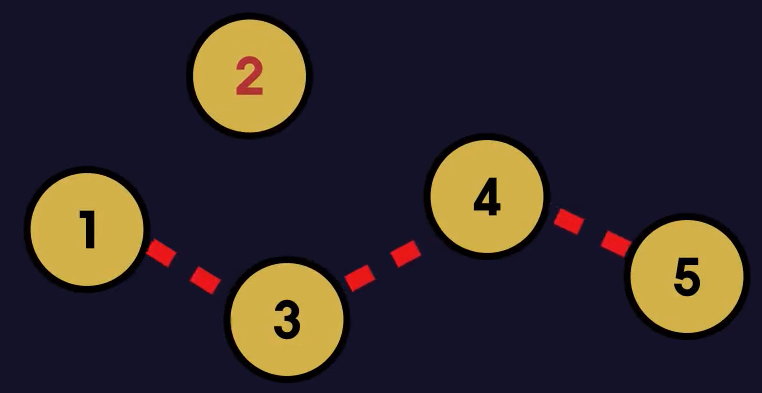
- 이러한 분산 및 연결은 노드(Node)가 있기에 가능하다.
- 노드의 구조는 (1). 데이터를 담는 변수 하나와 (2). 다음 노드를 가리키는 변수 하나를 가지고 있다.

- 데이터가 필요한 만큼 노드를 만들어 저장하고 다른 노드를 가리켜서 서로 연결해주면 된다.
- 이러한 모습 때문에 Linked List(연결 리스트) 라고 부르는 것이다.

- 위 그림에서 볼 수 있듯이 배열과 비슷하게 연결 리스트 또한 첫 노드의 주소만 알고 있으면 다른 모든 노드에 접근할 수 있다.
(1). 연결리스트 장점
1. 연결리스트에서 데이터를 추가하는 경우에는 빈 메모리 공간 아무곳에서 데이터를 생성한 후 연결만 해주면 되기 때문에 배열과 달리 초기 크기를 알아야 할 필요가 없다.
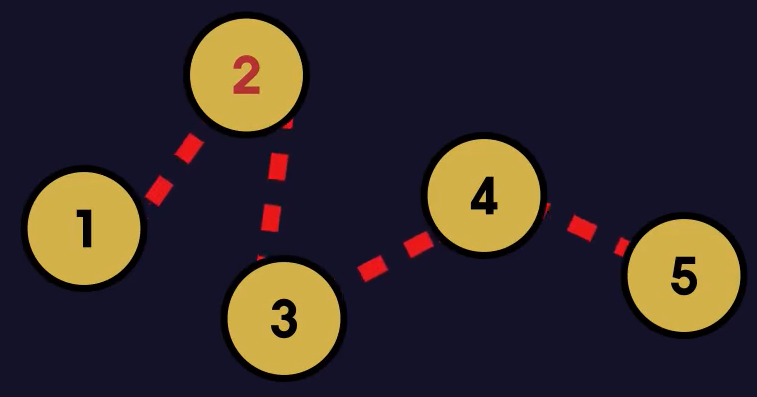
2. 배열의 경우 중간에 데이터를 삽입하면 그 뒤에 있는 데이터들이 모두 뒤로 밀려나기 때문에 오버헤드가 많이 든다.
2-1. 연결리스트의 경우 중간에 데이터를 삽입하려면 다음을 가리키는 노드만 바꿔주면 되기 때문에 작업이 간단하다.
(데이터의 삭제도 2번의 경우와 동일)


cf) 오버헤드
(2). 연결리스트 단점
- 배열은 메모리의 연속된 공간에 할당돼 있기 때문에 시작 주소만 알면 데이터 접근이 쉽다.
- 즉, 특정 index의 데이터를 찾고 싶다면 시작 주소에서 간단하게 index 만큼 더하기만 하면 되기 때문에 O(1)의 성능을 가진다.
- 그에 반해 연결 리스트는 데이터들이 전부 불연속적으로 떨어져 있기 때문에 원하는 데이터에 바로 접근할 수가 없다.
- 예를들어 4번째 노드에 원하는 데이터가 있다고 했을 때 아래 그림과 같은 일이 발생한다.
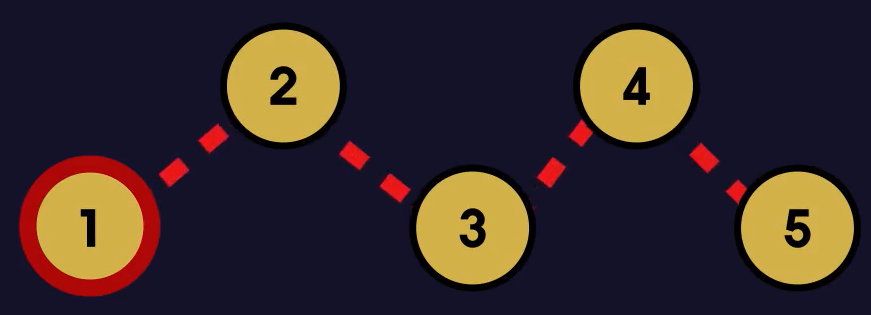
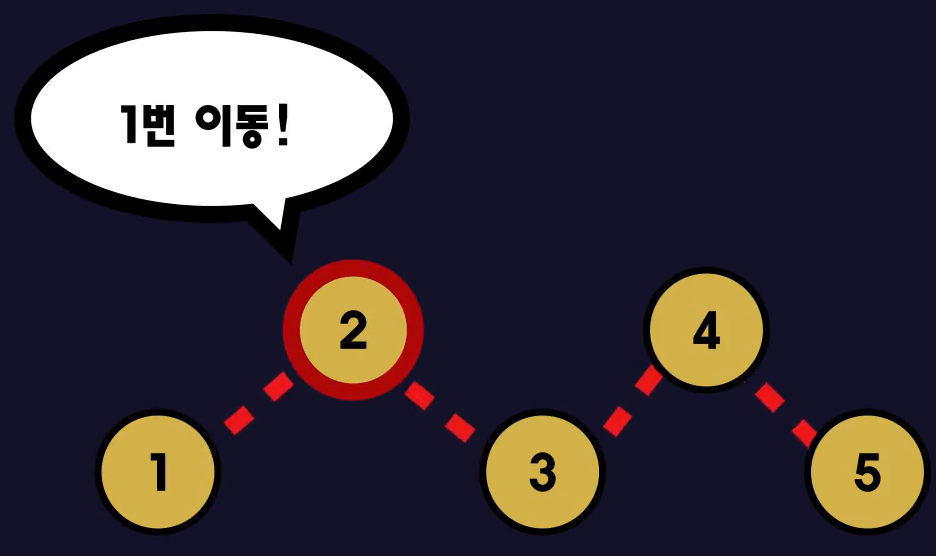

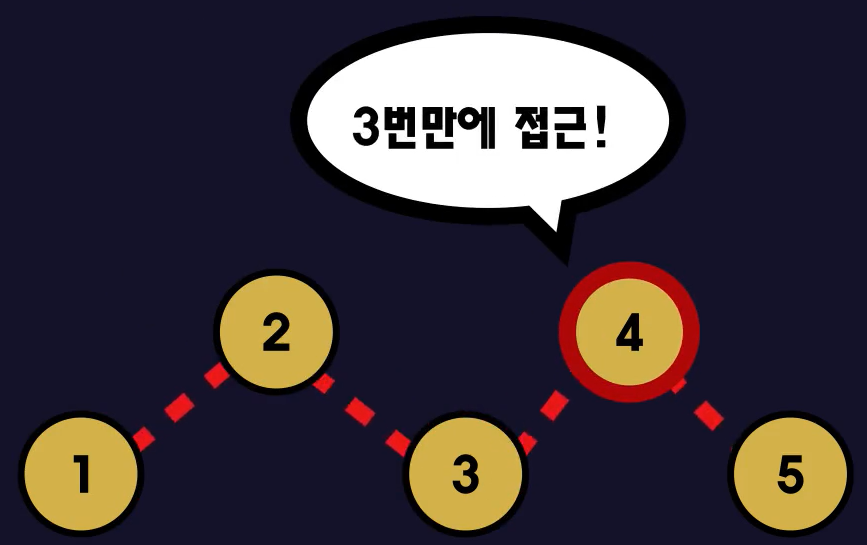
- 즉, 연결리스트에서 데이터 참조는 O(n)의 성능을 갖는다. cf) O(n) = 선형시간 알고리즘
정리
- 데이터의 수가 자주 바뀌지 않고 참조가 자주 일어나는 경우 배열을 사용하는게 좋다.
- 데이터의 추가 및 삭제가 자주 일어나는 경우 연결리스트를 사용하는게 좋다.
- 사실 데이터 자체의 크기가 작으면 배열을 사용하나 연결리스트를 사용하나 큰 차이가 없다.
- 하지만 데이터가 커지면 커질수록 어느 자료구조를 선택하느냐에 따라 성능의 차이는 훨씬 더 커질 것이다.
| 배열 | 연결리스트 | |
| 크기 | 고정(JS는 예외) | 동적 |
| 주소 | 메모리의 연속된 공간에 할당 | 메모리의 Heap 영역에 런타임 시(프로그램 실행 중)에 불연속적인 빈 공간에 할당 |
| 데이터 참조 성능 | O(1) 메모리의 연속된 공간에 할당 되기에 메모리 접근이 빠르다. |
O(n) 리스트의 시작부터 원하는 노드까지 접근해야 하기 때문에 느리다. |
| 새로운 데이터 삽입, 삭제 | O(n) 기존의 모든 데이터를 새 배열에 옮겨야 한다. |
O(n) 삽입하려는 노드까지 노드를 계속 타고가야 한다. |
● 의문점
- 내용을 정리하다보니 뭔가 이상한 점이 느껴졌다.
- 위에서 연결리스트의 장점을 얘기하는 부분에서 아래와 같이 강의에서 얘기했다.
연결리스트의 경우 중간에 데이터를 삽입하려면 다음을 가리키는 노드만 바꿔주면 되기 때문에 작업이 간단하다.
- 근데 배열과 연결리스트를 정리하는 표의 (새로운 데이터 삽입, 삭제) 부분에서는 아래와 같이 얘기했다.
O(n) : 삽입하려는 노드까지 노드를 계속 타고가야 한다.
- 간단한 작업인데.. 성능은 O(n) 이라... 말이 맞지 않는 것 같아서 강의를 만든 분한테 질문을 남겼고 아래와 같이 답변이 왔다.
질문

답변

- 정리하자면
1. 연결리스트 또한 중간에 데이터를 삽입(삭제)하려면 해당 노드까지 타고 타고해서 가야하기 때문에 O(n)의 성능을 가진다.
2. 연결리스트의 처음 or 끝에 데이터를 삽입(삭제)하려는 경우에만 O(1)의 성능을 가진다.
3. 즉, 연결리스트에서 참조, 삽입, 삭제를 위해 노드를 찾는 과정은 모두 O(n) 이며(처음과 끝 제외) 단지, 원하는 노드의 위치를 찾았을 때 배열에 비해서 데이터를 삽입(삭제)하는게 간단하다는 얘기이다.
'CS > 자료구조 및 알고리즘' 카테고리의 다른 글
| #7 큐(Queue) - 개념(FIFO : First In First Out) (0) | 2023.02.05 |
|---|---|
| #6 Stack(스택) - 개념(FILO : First In Last Out) (1) | 2023.02.02 |
| #4 배열 (0) | 2023.01.24 |
| #3 JS 실행 환경 구축 (0) | 2023.01.23 |
| #2 시간복잡도(좋은 알고리즘?) / 최악의 경우는 Big-O (0) | 2023.01.22 |
- Total
- Today
- Yesterday
- node.js
- db
- Spring Boot
- OS
- 코테
- Stream
- nosql
- 프로세스
- SQL
- jpa
- 자료구조
- Advanced Stream
- MySQL
- 알고리즘
- 빅데이터 분석기사
- 코딩테스트
- 메모리
- Java8
- Phaser3
- MongoDB
- API
- git
- 프로그래머스
- DART
- Phaser
- java
- SpringBoot
- 운영체제
- spring
- 빅데이터
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |