
티스토리 뷰
- SQL 없이 유저 생성, 조회, 수정 기능을 만들어 보자
- 이전 글에서 User Entity와 User table을 미리 매핑했기 때문에 아래의 작업들이 가능한 것이다.
1. 저장(INSERT)
- UserRepository interface를 User class와 같은 경로에 만들자

- JpaRepository를 상속하는 것만으로도 UserRepository는 Spring bean으로 등록된다.
- 따라서 UserRepository interface에는 @Repository Annotation을 따로 붙여줄 필요가 없다.
public void saveUser(UserCreateRequest request) {
// save는 원래 내장돼 있는 method
// INSERT 후에는 User 객체를 반환한다.
User user = userRepository.save(new User(request.getName(), request.getAge()));
System.out.println(user.getId());
}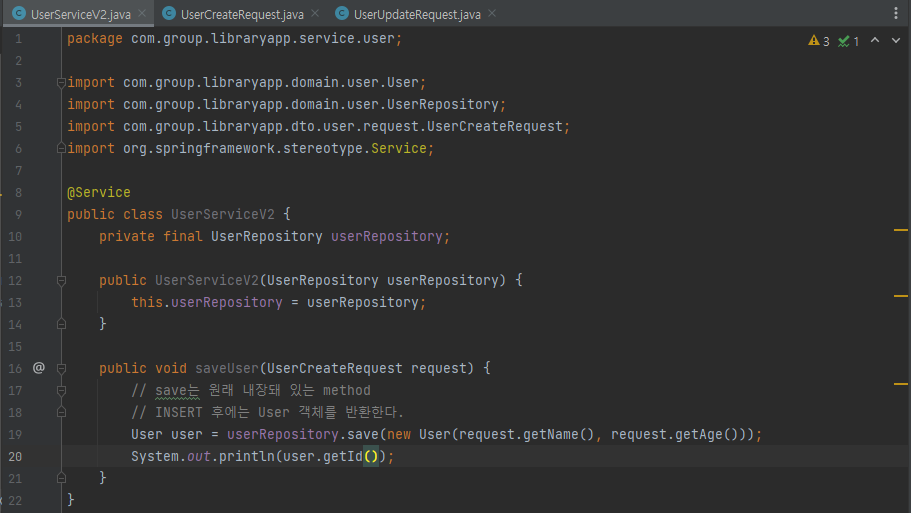
- 위와 같이 save 함수에 User 객체를 넣어주면 INSERT SQL이 자동으로 날라간다.
- INSERT 되고 난 후의 User에는 ID 값이 들어있다.
cf) 이전에 만들었던 com.group.libraryapp.repository.user 경로의 UserRepository는 UserJdbcRepository로 이름 변경

2. 조회(SELECT)
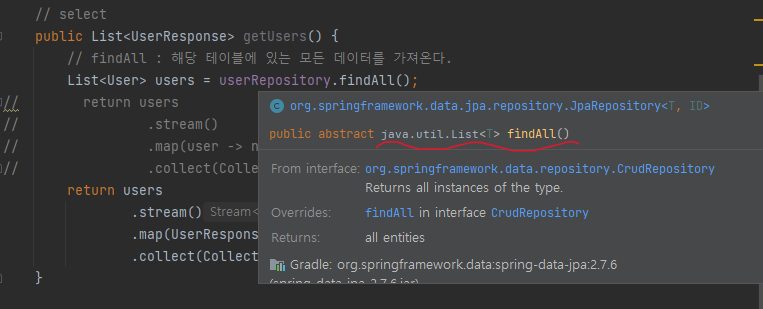
public List<UserResponse> getUsers() {
// findAll : 해당 테이블에 있는 모든 데이터를 가져온다.
List<User> users = userRepository.findAll();
// return users
// .stream()
// .map(user -> new UserResponse(user.getId(), user.getName(), user.getAge()))
// .collect(Collectors.toList());
return users
.stream()
.map(UserResponse::new)
.collect(Collectors.toList());
}
userRepository.findAll() == SELECT * FROM USER;
3. 수정(UPDATE)
1. ID를 이용해 User를 가져와 User가 있는지 없는지 확인
2. 없으면 IllegalArgumentException throw
3. 있으면 UPDATE 쿼리를 날려 데이터를 수정
- 자동으로 User의 name이 바뀌어 있는 것을 확인하고 바뀐 name을 기준으로 UPDATE SQL이 날라간다.
1. findById 함수를 이용해 id를 기준으로 1개의 User 데이터를 가져온다. cf) findById 함수도 내장 함수다.
2. Optional의 orElseThrow를 사용해 User가 없다면 예외를 던진다.
3. User가 있다면 User 객체의 name을 업데이트 한 다음에 save 함수를 호출한다.
4. 그러면 자동으로 UPDATE SQL이 날라가게 된다.
public void updateUser(UserUpdateRequest request) {
// findById는 Optional<User>를 반환, findById 함수도 내장 함수이다.
// ID로 조회한 후 User가 없으면 예외, 있으면 해당하는 User 객체 반환
User user = userRepository.findById(request.getId()) // SELECT * FROM USER WHERE ID = ?
.orElseThrow(IllegalArgumentException::new);
user.updateName(request.getName());
userRepository.save(user);
}
● 정리
save : 주어지는 객체를 저장하거나 업데이트 시켜준다.
findAll : 주어지는 객체가 매핑된 테이블의 모든 데이터를 가져온다.
findById : id를 기준으로 특정한 1개의 데이터를 가져온다.
Q. 그나저나 도대체 어떠한 원리가 숨겨져 있길래 SQL을 직접 작성하지 않아도 동작하는 것일까?
A.
- JPA가 자동으로 처리한 것은 맞는데 이것이 100% 맞는 얘기는 아니다.
- 정확히 말하면 Spring Data JPA가 처리해 준 것이다.(JPA와 Spring Data JPA는 조금 다르다.)
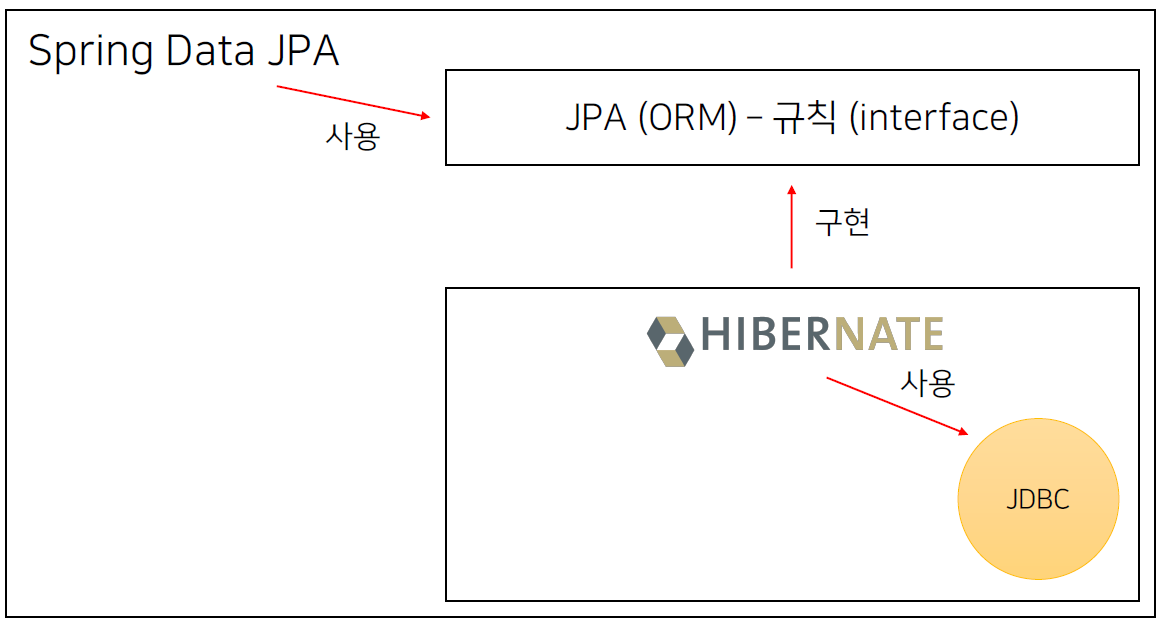
Spring Data JPA
- 복잡한 JPA 코드를 Spring과 함께 쉽게 사용할 수 있도록 도와주는 라이브러리이다.
- 사실 위에서 사용한 save, findAll, findById 같은 함수는 JPA 코드가 아닌 Spring Data JPA 코드이다.
- 즉, Spring Data JPA는 복잡한 JPA 코드를 한 번 감싸서 우리가 쉽게 이용할 수 있도록 해주는 것이다.

'Backend > Spring' 카테고리의 다른 글
| #26 JPA를 이용해 SQL 날리기 with Spring Data JPA2 (0) | 2023.09.26 |
|---|---|
| #25 트랜잭션 - 이론 (0) | 2023.09.25 |
| #23 Entity Class (0) | 2023.09.10 |
| #22 JPA - 등장 (0) | 2023.09.05 |
| #21 Spring bean을 등록하는 방법 / Spring bean을 주입 받는 방법 (0) | 2023.09.03 |
- Total
- Today
- Yesterday
- java
- db
- Phaser
- Advanced Stream
- 빅데이터 분석기사
- MySQL
- 빅데이터
- 프로세스
- jpa
- API
- Stream
- 코테
- node.js
- 프로그래머스
- spring
- MongoDB
- SpringBoot
- 메모리
- Spring Boot
- DART
- 운영체제
- 자료구조
- SQL
- Phaser3
- Java8
- 코딩테스트
- OS
- 알고리즘
- nosql
- git
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |