
티스토리 뷰
● 도입
- FIFO 알고리즘은 일괄처리 시스템에 적절하기에 시분할 처리 시스템에서는 쓰기가 힘들고 SJF 알고리즘은 프로세스 종료시간을 예측할 수 없기에 구현이 힘들다.
- FIFO 알고리즘은 먼저 들어온 프로세스가 전부 끝나야 다음 프로세스가 실행되는 알고리즘이다.
- 이러한 FIFO 알고리즘의 문제를 해결하기 위해서는 한 프로세스에게 일정 시간만큼 CPU를 할당한 후 해당 시간이 지나면 강제로 다른 프로세스에게 동일한 일정 시간만큼 CPU를 할당해주면 된다.
- 강제로 CPU를 뺏긴 프로세스는 Queue의 가장 뒷부분으로 밀려난다.
- 이러한 알고리즘을 RR 알고리즘이라고 한다.

ex) 아래는 (할당시간 = 2초)일 때의 예시이다.


- (할당시간 = 2초)이기에 프로세스1을 2초간 실행한 후 남은 8초는 프로세스2의 뒤로 밀려난다.(Queue의 가장 뒷부분으로 밀려난다.)

● Round Robin Scheduling
- 프로세스에게 CPU를 할당하는 일정 시간을 Time Quantum 또는 Time Slice 라고 한다.
- (Time Slice = 10초)라고 했을 때 Round Robin Scheduling의 성능을 알아보자(= 평균 대기 시간을 구해보자)
cf) 스케줄링의 성능은 평균 대기 시간으로 평가한다.
ex)

- (프로세스1 = P1 / 프로세스2 = P2 / 프로세스3 = P3)라고 가정한다.
- (P1의 Burst Time = 25초 / P2의 Burst Time = 4초 / P3의 Burst Time = 10초)이다.
- 3개의 프로세스들은 동시에 Queue에 들어왔고 실행 순서는 P1, P2, P3 이다.
1.
- P1은 Queue에 들어오자마자 바로 실행되기 때문에 (대기시간 = 0초)이다.
- P1은 (Time Slice = 10초)만큼 실행하다가 시간(10초)을 초과했기 때문에 P2에게 CPU를 뺏기고 P1의 남은 작업은 Queue의 가장 뒤로 이동한다.



현재 대기시간 = 0초
2.
- P2는 P1이 실행되는 10초를 기다렸기에 P2의 (대기시간 = 10초)이다.
- P2의 (Burst Time = 4초)이기에 4초가 지나면 CPU를 P3에게 양보한 후 작업을 종료한다.
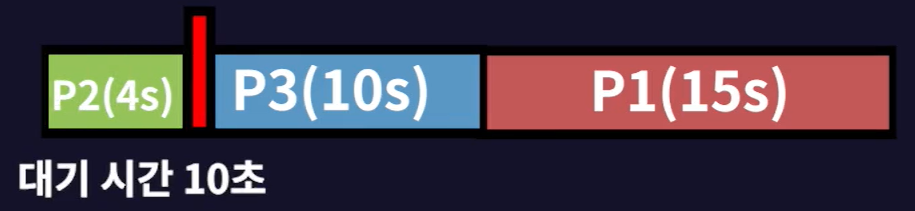
현재 대기시간 = 0초 + 10초
3.
- P3는 P1과 P2의 실행이 완료될 때까지 14초를 기다렸다. 따라서 P3의 (대기시간 = 14초)이다.
- P3의 (Burst Time = 10초)이기에 10초가 지나면 작업을 종료한다.


현재 대기시간 = 0초 + 10초 + 14초
4.
- 다시 Queue의 가장 뒤에 있던 P1이 실행되는데 이때 P1은 P2와 P3의 실행이 완료될 때까지 14초를 기다렸다.
- 따라서 P1의 (대기시간 = 14초)이다.
- 현재 P1의 (Burst Time = 15초)로 (Time Slice = 10초)보다 크기 때문에 Time Slice 값인 10초 동안만 실행된다.


현재 대기시간 = 0초 + 10초 + 14초 + 14초
5.
- (Burst Time = 5초)인 P1이 Queue의 마지막으로 이동한다.
- 이때는 대기중인 다른 프로세스가 없기 때문에 바로 P1이 실행된다.

- 이때 P1의 (대기시간 = 0초)이다.
- P1이 끝난 후 곧바로 동일한 프로세스인 P1이 다시 실행되는 것이기에 대기시간이 없는 것이다.
현재 대기시간 = 0초 + 10초 + 14초 + 14초 + 0초
6.
- 위의 과정에 대한 평균 대기 시간을 구해보자

P1의 첫 번째 대기시간 = 0초
P2의 대기시간 = 10초
P3의 대기시간 = 14초
P1의 두 번째 대기시간 = 14초
P1의 세 번째 대기시간 = 0초
- 위의 총합은 (0 + 10 + 14 + 14 + 0 = 38)초 이다.
- 이것을 프로세스 갯수인 3으로 나누면 (38 / 3 = 12.67)초이다.
- 즉, (평균 대기 시간 = 12.67)초 인 것이다.● RR과 FIFO의 평균 대기 시간이 비슷할 때
- 위의 예시에서 RR 알고리즘의 (평균 대기 시간 = 12.67초) / FIFO 알고리즘의 (평균 대기 시간 = 18초)가 나온다.
- 아래 그림은 FIFO 알고리즘의 평균 대기 시간이다.

- 이렇게 보면 RR 알고리즘이 FIFO 알고리즘 보다 무조건 빠르다고 생각할 수 있다.
- 하지만 경우에 따라서는 RR 알고리즘과 FIFO 알고리즘의 평균 대기 시간이 비슷할 수도 있다.
- 만약 비슷한 경우라면 RR 알고리즘이 더 비효율적인 방식이라고 할 수 있다.
- RR 알고리즘은 컨텍스트 스위칭이 있기 때문에 컨텍스트 스위칭 시간이 더 추가되기 때문이다.
- 이러한 연유로 RR 알고리즘의 성능은 Time Slice 값의 영향을 많이 받는다.
1. Time Slice가 큰 경우
- 이론적으로 (Time Slice = 무한대의 값)이라면 먼저 들어온 프로세스의 작업이 종료될 때까지 CPU를 차지하는 것이므로
이는 FIFO 알고리즘과 다를게 없다.
2. Time Slice = 5초
- (Time Slice = 5초)일 때 크롬과 멜론을 실행하면 크롬이 5초 동안 작동하다가 멈추고 멜론이 5초 동안 작동하다가 멈추는 과정이 반복되기에 사용자는 컴퓨터가 렉이라도 걸린 것처럼 느낄 것이다.

3. Time Slice가 매우 작은 경우
- (Time Slice = 1ms)라고 해보자
- 이 경우 사용자는 크롬과 멜론이 동시에 동작하는 것처럼 느낄 것이다.

- 그러나 Time Slice를 이렇게 매우 작게 설정하면 컨텍스트 스위칭이 자주 일어나기에 Time Slice에서 실행되는 프로세스의 처리량보다 컨텍스트 스위칭을 처리하는 양이 훨씬 더 많아지기에 배보다 배꼽이 커지는 상황이 발생한다.
- 이러한 경우를 "오버헤드가 너무 크다."라고 한다.
- 최적의 Time Slice는 여러 프로세스가 버벅거리지 않고 동시에 실행되는 것처럼 느껴지면서 오버헤드가 너무 크지 않은 값이다.
- Windows의 경우 (Time Slice = 20ms), Unix에서는 (Time Slice = 100ms)로 설정하고 있다.
'CS > 운영체제' 카테고리의 다른 글
| #19 프로세스 동기화 - 프로세스 간 통신 (0) | 2023.05.08 |
|---|---|
| #18 스케줄링 알고리즘 - MLFQ(Multi Level Feedback Queue) (0) | 2023.03.26 |
| #16 스케줄링 알고리즘 - SJF(Shortest Job First) (0) | 2023.03.14 |
| #15 스케줄링 알고리즘 - FIFO(First In First Out) / 평균 대기 시간 (0) | 2023.03.13 |
| #14 스케줄링 목표 (0) | 2023.03.12 |
- Total
- Today
- Yesterday
- SpringBoot
- java
- nosql
- 자료구조
- 알고리즘
- 메모리
- db
- Advanced Stream
- git
- 프로세스
- 코딩테스트
- MongoDB
- Phaser
- DART
- MySQL
- jpa
- spring
- 빅데이터 분석기사
- API
- node.js
- Java8
- 코테
- 프로그래머스
- 빅데이터
- Phaser3
- OS
- Stream
- SQL
- Spring Boot
- 운영체제
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |